Several years ago there was a lot of hype around the potential of big data, taking data that was too large for conventional data processing and applying new technologies and discovering various insights and solutions for businesses. Since 2012, the trend in big data has generally been positive but there have been challenges. Studies by Gartner research have indicated high failure rates with big data projects and how a large proportion of big data studies don’t make it to the transformational business intelligence stage.
Some of the main challenges related to big data are related to the unstructured form of the information, the overall quality and inaccuracies in the data. Generating data that represents what it is as opposed to the multiple options available can be complicated. With the growth of new technology tools available for processing and analysis, it does seem that quality may not be regarded on the same level as quantity. Data quantity has grown considerably in the last few years. It’s believed that nearly 90% of global data was generated in just the last 2 years. This significant growth is facilitating the development of data science and machine learning in global business analytics.
We are approaching what can be regarded as one of the most challenging years in history, a time when nearly all markets were disrupted by the pandemic. Many predictive systems which were developed based on analysis and forecasting of historical data have also been affected.
When looking at Big Data AI for humans and their related behaviours, attitudes and intentions, many of which are driven by subconscious decisions rather than specific clicks, overall success has been declining. Many companies are actively exploring the value of big data by researching and analysing customer transactions and customer data files.
Transactional data, for example, doesn’t provide any detail on why a customer bought something or whether it was a gift for someone. Customer data files commonly have incomplete information or data inaccuracies due to changes in the circumstances of the customer.
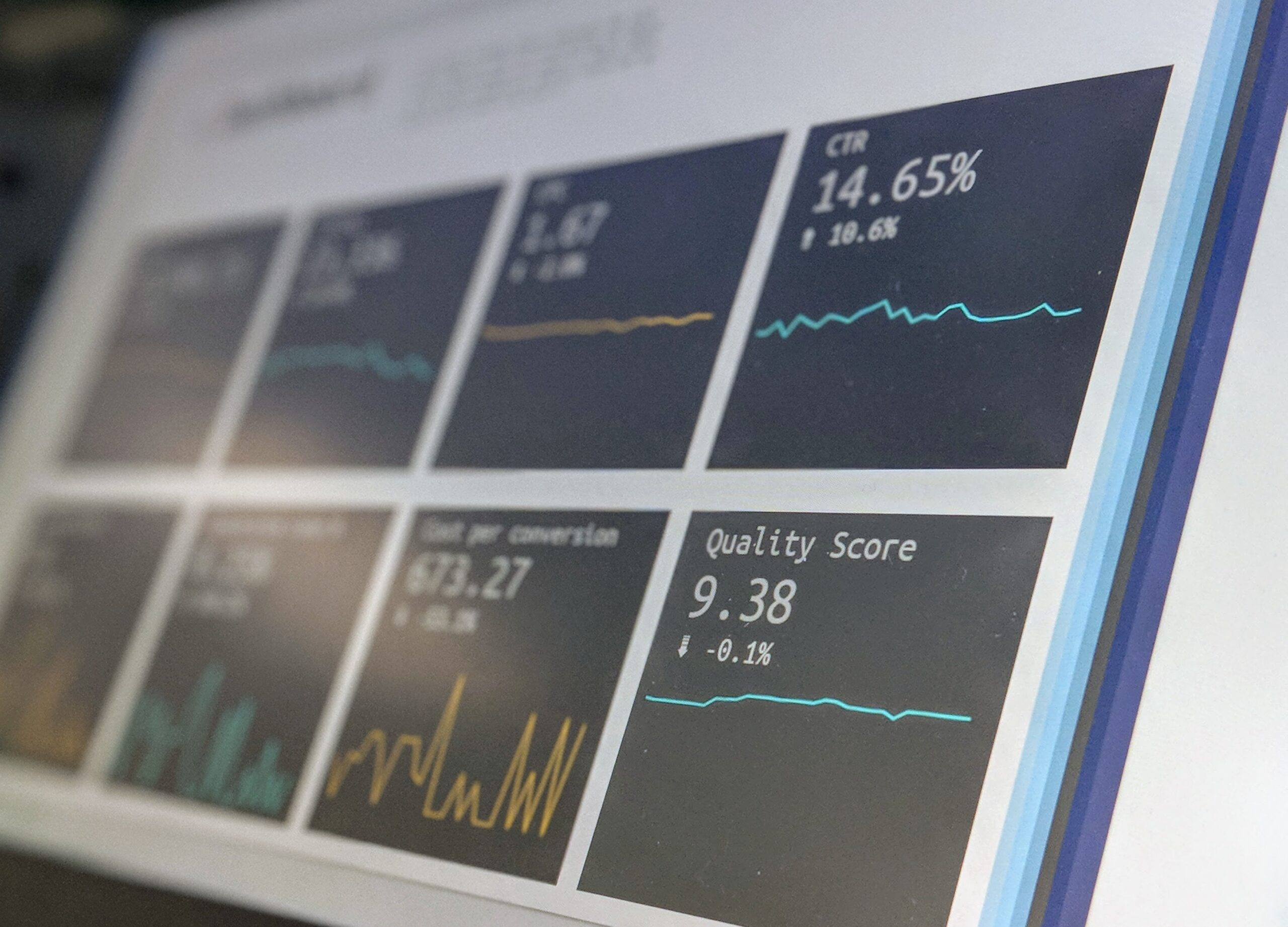
For the marketing and advertising industry, investment in digital advertising represents the biggest sector of advertising in North America. There have been many challenges with this growth of digital advertising. Several studies have identified the inaccuracies and unreliability of big data ad targeting models. Further reports have suggested that many of these models are based on data derived and collected without the consent of the customer or combines data sets generated with bot data. Applying this type of data into a model only means further inaccuracies with the final product.
In the finance and investment community, many businesses have been very interesting in integrating big data technology. In the investment field, big data has been renamed as ‘Alternative Data’ and includes anything from credit card transactions, social media, satellite images and web browsing. One of the most recent businesses to employ alternative data in this field was a hedge fund called Renaissance Technologies. Hedge funds have experienced similar challenges to other businesses by adopting big data systems. This includes potential data provenance risks i.e. does the procurement of data meet all necessary terms and conditions, understanding the accuracy of the data sets and general privacy risks in terms of how the data is generated.
A further study by Bloomberg has suggested that Renaissance Technologies models and returns in the last month have declined and some experts believe their models do not apply to the current environment. Industry professionals believe the system is reliant on models that are trained by historical data, another example of feeding a system with bad data and generating bad outcomes.
What is the solution?
The initial step is to ensure that data scientists consider the true accuracy, validity and compliance of all data sets being used as inputs. It’s very challenging interpreting bad data sets. Consideration needs to be made towards the variables with data sets. Humans represent more than just clicks and customers data sources are needed to understand and connect digital data with the reality of customer behaviour. If accuracy and validity are covered first, then the outcomes are likely to improve. Spending more time on these areas at the start of the project will enable data scientists to greatly improve the success rate for big data projects.
If data accuracy and validity are job one, it follows that outcomes should improve. By paying more attention to the accuracy, quality and validity of the data at the beginning of ML projects, Data Scientists may move beyond the 85% failure rate for Big Data projects.
Written by:
Connect with :
![]()